Perceptron Training Rule for Linear Classification for Artificial Neural Networks in Machine Learning – 17CS73
Video Tutorial
A perceptron unit is used to build the ANN system.

A perceptron takes a vector of real-valued inputs, calculates a linear combination of these inputs, then outputs a 1 if the result is greater than some threshold and -1 otherwise.
More precisely, given inputs x1 through xn, the output o(x1, . . . , xn) computed by the perceptron is

where each wi is a real-valued constant, or weight, that determines the contribution of input xi to the perceptron output.
One way to learn an acceptable weight vector is to begin with random weights, then iteratively apply the perceptron to each training example, modifying the perceptron weights whenever it misclassifies an example.
This process is repeated, iterating through the training examples as many times as needed until the perceptron classifies all training examples correctly.
Weights are modified at each step according to the perceptron training rule, which revises the weight wi associated with input xi according to the rule.
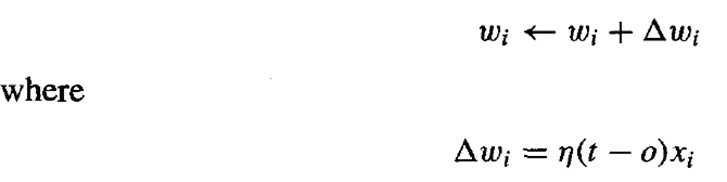
Perceptron Training Rule
Perceptron_training_rule (X, η)
initialize w (wi <- an initial (small) random value)
repeat
for each training instance (x, tx) ∈ X
compute the real output ox = Activation(Summation(w.x))
if (tx ≠ ox)
for each wi
wi <- wi + ∆𝑤𝑖
∆𝑤𝑖 <- η (tx - ox)xi
end for
end if
end for
until all the training instances in X are correctly classified
return wSummary
This tutorial discusses the Perceptron Training Rule for Linear Classification in Machine Learning. If you like the tutorial share it with your friends. Like the Facebook page for regular updates and YouTube channel for video tutorials.