Python Program to Implement the Naïve Bayesian Classifier using API for document classification
Exp. No. 6. Assuming a set of documents that need to be classified, use the naïve Bayesian Classifier model to perform this task. Built-in Java classes/API can be used to write the program. Calculate the accuracy, precision, and recall for your data set.
Video tutorial
Bayes’ Theorem is stated as:

Where,
P(h|D) is the probability of hypothesis h given the data D. This is called the posterior probability.
P(D|h) is the probability of data d given that the hypothesis h was true.
P(h) is the probability of hypothesis h being true. This is called the prior probability of h. P(D) is the probability of the data. This is called the prior probability of D
After calculating the posterior probability for a number of different hypotheses h, and is interested in finding the most probable hypothesis h ∈ H given the observed data D. Any such maximally probable hypothesis is called a maximum a posteriori (MAP) hypothesis.
Bayes theorem to calculate the posterior probability of each candidate hypothesis is hMAP is a MAP hypothesis provided.

(Ignoring P(D) since it is a constant)
CLASSIFY_NAIVE_BAYES_TEXT (Doc)
Return the estimated target value for the document Doc. ai denotes the word found in the ith position within Doc.
- positions ← all word positions in Doc that contain tokens found in Vocabulary
- Return VNB, where
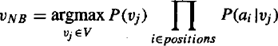
![]() Data set:
Data set:
Save dataset in .csv format
| Text Documents | Label | |
| 1 | I love this sandwich | pos |
| 2 | This is an amazing place | pos |
| 3 | I feel very good about these beers | pos |
| 4 | This is my best work | pos |
| 5 | What an awesome view | pos |
| 6 | I do not like this restaurant | neg |
| 7 | I am tired of this stuff | neg |
| 8 | I can’t deal with this | neg |
| 9 | He is my sworn enemy | neg |
| 10 | My boss is horrible | neg |
| 11 | This is an awesome place | pos |
| 12 | I do not like the taste of this juice | neg |
| 13 | I love to dance | pos |
| 14 | I am sick and tired of this place | neg |
| 15 | What a great holiday | pos |
| 16 | That is a bad locality to stay | neg |
| 17 | We will have good fun tomorrow | pos |
| 18 | I went to my enemy’s house today | neg |
Python Program to Implement and Demonstrate Naïve Bayesian Classifier using API for document classification
"""
6. Assuming a set of documents that need to be classified, use the naïve Bayesian Classifier model to perform this task.
Built-in Java classes/API can be used to write the program. Calculate the accuracy, precision, and recall for your data set
"
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
msg=pd.read_csv('naivetext.csv',names=['message','label'])
print('The dimensions of the dataset',msg.shape)
msg['labelnum']=msg.label.map({'pos':1,'neg':0})
X=msg.message
y=msg.labelnum
#splitting the dataset into train and test data
xtrain,xtest,ytrain,ytest=train_test_split(X,y)
print ('\n the total number of Training Data :',ytrain.shape)
print ('\n the total number of Test Data :',ytest.shape)
#output the words or Tokens in the text documents
cv = CountVectorizer()
xtrain_dtm = cv.fit_transform(xtrain)
xtest_dtm=cv.transform(xtest)
print('\n The words or Tokens in the text documents \n')
print(cv.get_feature_names())
df=pd.DataFrame(xtrain_dtm.toarray(),columns=cv.get_feature_names())
# Training Naive Bayes (NB) classifier on training data.
clf = MultinomialNB().fit(xtrain_dtm,ytrain)
predicted = clf.predict(xtest_dtm)
#printing accuracy, Confusion matrix, Precision and Recall
print('\n Accuracy of the classifier is',metrics.accuracy_score(ytest,predicted))
print('\n Confusion matrix')
print(metrics.confusion_matrix(ytest,predicted))
print('\n The value of Precision', metrics.precision_score(ytest,predicted))
print('\n The value of Recall', metrics.recall_score(ytest,predicted))Output
The dimensions of the dataset (18, 2)
1. I love this sandwich
2. This is an amazing place
3. I feel very good about these beers
4. This is my best work
5. What an awesome view
6. I do not like this restaurant
7. I am tired of this stuff
8. I can’t deal with this
9. He is my sworn enemy
10. My boss is horrible
11. This is an awesome place
12. I do not like the taste of this juice
13. I love to dance
14. I am sick and tired of this place
15. What a great holiday
16. That is a bad locality to stay
17. We will have good fun tomorrow
18. I went to my enemy’s house today
Name: message, dtype: object 0 1
1 1
2 1
3 1
4 1
5 0
6 0
7 0
8 0
9 0
10 1
11 0
12 1
13 0
14 1
15 0
16 1
17 0
Name: labelnum, dtype: int64
The total number of Training Data: (13,) The total number of Test Data: (5,)
The words or Tokens in the text documents
[‘about’, ‘am’, ‘amazing’, ‘an’, ‘and’, ‘awesome’, ‘beers’, ‘best’, ‘can’, ‘deal’, ‘do’, ‘enemy’, ‘feel’,
‘fun’, ‘good’, ‘great’, ‘have’, ‘he’, ‘holiday’, ‘house’, ‘is’, ‘like’, ‘love’, ‘my’, ‘not’, ‘of’, ‘place’,
‘restaurant’, ‘sandwich’, ‘sick’, ‘sworn’, ‘these’, ‘this’, ‘tired’, ‘to’, ‘today’, ‘tomorrow’, ‘very’, ‘view’, ‘we’, ‘went’, ‘what’, ‘will’, ‘with’, ‘work’]
Accuracy of the classifier is 0.8
Confusion matrix
[[2 1]
[0 2]]
The value of Precision 0.6666666666666666
The value of Recall 1.0
Summary
This tutorial discusses how to Implement and demonstrate the Naïve Bayesian Classifier in Python using API. If you like the tutorial share it with your friends. Like the Facebook page for regular updates and YouTube channel for video tutorials.