Python Program to Implement Decision Tree ID3 Algorithm
Exp. No. 3. Write a program to demonstrate the working of the decision tree based ID3 algorithm. Use an appropriate data set for building the decision tree and apply this knowledge to classify a new sample.
Decision Tree ID3 Algorithm Machine Learning
ID3(Examples, Target_attribute, Attributes)
Examples are the training examples.
Target_attribute is the attribute whose value is to be predicted by the tree.
Attributes is a list of other attributes that may be tested by the learned decision tree.
Returns a decision tree that correctly classifies the given Examples.
Create a Root node for the tree
If all Examples are positive, Return the single-node tree Root, with label = +
If all Examples are negative, Return the single-node tree Root, with label = -
If Attributes is empty, Return the single-node tree Root,
with label = most common value of Target_attribute in Examples
Otherwise Begin
A ← the attribute from Attributes that best* classifies Examples
The decision attribute for Root ← A
For each possible value, vi, of A,
Add a new tree branch below Root, corresponding to the test A = vi
Let Examples vi, be the subset of Examples that have value vi for A
If Examples vi , is empty
Then below this new branch add a leaf node with
label = most common value of Target_attribute in Examples
Else
below this new branch add the subtree
ID3(Examples vi, Targe_tattribute, Attributes – {A}))
End
Return Root
The best attribute is the one with highest information gain
ENTROPY:
Entropy measures the impurity of a collection of examples.
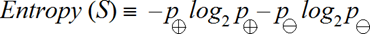
Where, p+ is the proportion of positive examples in S
p– is the proportion of negative examples in S.
INFORMATION GAIN:
Information gain, is the expected reduction in entropy caused by partitioning the examples according to this attribute.
The information gain, Gain(S, A) of an attribute A, relative to a collection of examples S, is defined as
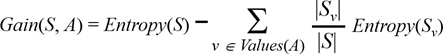
Dataset:
PlayTennis Dataset is saved as .csv (comma separated values) file in the current working directory otherwise use the complete path of the dataset set in the program:
| Day | Outlook | Temperature | Humidity | Wind | PlayTennis |
| D1 | Sunny | Hot | High | Weak | No |
| D2 | Sunny | Hot | High | Strong | No |
| D3 | Overcast | Hot | High | Weak | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | Normal | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Strong | Yes |
| D8 | Sunny | Mild | High | Weak | No |
| D9 | Sunny | Cool | Normal | Weak | Yes |
| D10 | Rain | Mild | Normal | Weak | Yes |
| D11 | Sunny | Mild | Normal | Strong | Yes |
| D12 | Overcast | Mild | High | Strong | Yes |
| D13 | Overcast | Hot | Normal | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
Click here to download the dataset
Python Program to Implement and Demonstrate FIND-S Algorithm
Import libraries and read data using read_csv() function. Remove the target from the data and store attributes in the features variable.
import pandas as pd
import math
import numpy as np
data = pd.read_csv("Dataset/4-dataset.csv")
features = [feat for feat in data]
features.remove("answer")Create a class named Node with four members children, value, isLeaf and pred.
class Node:
def __init__(self):
self.children = []
self.value = ""
self.isLeaf = False
self.pred = ""Define a function called entropy to find the entropy oof the dataset.
def entropy(examples):
pos = 0.0
neg = 0.0
for _, row in examples.iterrows():
if row["answer"] == "yes":
pos += 1
else:
neg += 1
if pos == 0.0 or neg == 0.0:
return 0.0
else:
p = pos / (pos + neg)
n = neg / (pos + neg)
return -(p * math.log(p, 2) + n * math.log(n, 2))Define a function named info_gain to find the gain of the attribute
def info_gain(examples, attr):
uniq = np.unique(examples[attr])
#print ("\n",uniq)
gain = entropy(examples)
#print ("\n",gain)
for u in uniq:
subdata = examples[examples[attr] == u]
#print ("\n",subdata)
sub_e = entropy(subdata)
gain -= (float(len(subdata)) / float(len(examples))) * sub_e
#print ("\n",gain)
return gain
Define a function named ID3 to get the decision tree for the given dataset
def ID3(examples, attrs):
root = Node()
max_gain = 0
max_feat = ""
for feature in attrs:
#print ("\n",examples)
gain = info_gain(examples, feature)
if gain > max_gain:
max_gain = gain
max_feat = feature
root.value = max_feat
#print ("\nMax feature attr",max_feat)
uniq = np.unique(examples[max_feat])
#print ("\n",uniq)
for u in uniq:
#print ("\n",u)
subdata = examples[examples[max_feat] == u]
#print ("\n",subdata)
if entropy(subdata) == 0.0:
newNode = Node()
newNode.isLeaf = True
newNode.value = u
newNode.pred = np.unique(subdata["answer"])
root.children.append(newNode)
else:
dummyNode = Node()
dummyNode.value = u
new_attrs = attrs.copy()
new_attrs.remove(max_feat)
child = ID3(subdata, new_attrs)
dummyNode.children.append(child)
root.children.append(dummyNode)
return rootDefine a function named printTree to draw the decision tree
def printTree(root: Node, depth=0):
for i in range(depth):
print("\t", end="")
print(root.value, end="")
if root.isLeaf:
print(" -> ", root.pred)
print()
for child in root.children:
printTree(child, depth + 1)Define a function named classify to classify the new example
def classify(root: Node, new):
for child in root.children:
if child.value == new[root.value]:
if child.isLeaf:
print ("Predicted Label for new example", new," is:", child.pred)
exit
else:
classify (child.children[0], new)Finally, call the ID3, printTree and classify functions
root = ID3(data, features)
print("Decision Tree is:")
printTree(root)
print ("------------------")
new = {"outlook":"sunny", "temperature":"hot", "humidity":"normal", "wind":"strong"}
classify (root, new)Output:

Decision Tree is:
outlook
overcast -> ['yes']
rain
wind
strong -> ['no']
weak -> ['yes']
sunny
humidity
high -> ['no']
normal -> ['yes']
------------------
Predicted Label for new example {'outlook': 'sunny', 'temperature': 'hot', 'humidity': 'normal', 'wind': 'strong'} is: ['yes']Solved Numerical Examples and Tutorial on Decision Trees Machine Learning:
1. How to build a decision Tree for Boolean Function Machine Learning
2. How to build a decision Tree for Boolean Function Machine Learning
3. How to build Decision Tree using ID3 Algorithm – Solved Numerical Example – 1
4. How to build Decision Tree using ID3 Algorithm – Solved Numerical Example -2
5. How to build Decision Tree using ID3 Algorithm – Solved Numerical Example -3
6. Appropriate Problems for Decision Tree Learning Machine Learning Big Data Analytics
7. How to find the Entropy and Information Gain in Decision Tree Learning
8. Issues in Decision Tree Learning Machine Learning
9. How to Avoid Overfitting in Decision Tree Learning, Machine Learning, and Data Mining
10. How to handle Continuous Valued Attributes in Decision Tree Learning, Machine Learning
Summary
This tutorial discusses how to Implement and demonstrate the Decision Tree ID3 Algorithm in Python. The training data is read from a .CSV file. If you like the tutorial share it with your friends. Like the Facebook page for regular updates and YouTube channel for video tutorials.
sir why we used the word “answer ” in our code
Answer is the target collumn name